

开yun体育网当疏导的前缀出现并掷中缓存时-ky体育官网登录入口网页版(中国)有限公司官网
 智东西
智东西
智东西10月15日音书,10月14日,小米和北京大学聚会签字的论文发表于arXiv,曾被曝获小米集团首创东谈主兼CEO雷军以千万年薪招募的DeepSeek“天才青娥”罗福莉,出当今了这篇论文的通信作家之列,但值得留意的是,论文作家中并莫得标注罗福莉属于小米大模子团队。

通信作家中的罗福莉是95后,她本科就读于北京师范大学筹商机专科,硕士毕业于北京大学筹商说话学辩论所筹商说话学专科。随后罗福莉曾在阿里巴巴达摩院主导蛊惑了多说话预测验模子VECO,并鼓舞了AliceMind的开源职责,2022年入职DeepSeek,参与了MoE大模子DeepSeek-V2的研发。客岁年底,小米被曝以千万年薪挖角DeepSeek-V2中枢蛊惑者之一罗福莉,使其冲上热搜,但两边于今都未公开声明是否精采入职小米。

▲DeepSeek“天才青娥”罗福莉(图源:罗福莉个东谈主公众号)
这篇论文提议了耕种MoE模子强化学习测验的新模范Rollout Routing Replay(R3)。实践适度阐发注解,R3的举座性能优于GRPO、TIS这类强化学习边界耕种模子性能的优化算法,且引入R3的统共组合模范全历程无崩盘,测验历程中测验-推理KL散度等耐久较低,在不影响测验速率的情况下,使得极点token比例减少一个量级。
当下,强化学习(RL)已成为耕种大说话模子智商的关节模范。相干词,在MoE模子中,路由机制时常会引入不领略性,致使导致强化学习测验崩溃,但现存的引入伏击性采样机制等并不成耕种测验领略性。不同于此前选用诸如丢弃各别较大的数据之类的变通模范,这篇论文的辩论东谈主员但愿通过处分路由分散也即是R3来根人道处分这个问题。
论文地址:https://arxiv.org/pdf/2510.11370
一、破解强化学习崩溃的关节模范,小米团队提议R3强化学习已成为大说话模子后期测验的基石,哄骗大限制强化学习,大模子更深远、更无为推理,取得处分复杂问题所需的高档智商,但其面对的关节挑战是何如均衡服从和领略性。
当代强化学习框架频繁使用不同的引擎进行推理和测验用于部署,但这种架构上的离别可能导致token概率出现不对,致使可能导致疼痛性的强化学习崩溃。相干词,现存的创新模范并不成齐备处分MoE模子上进行强化学习测验时出现的强化学习离线战略问题。
辩论东谈主员提议的R3,其职责旨趣是在序列生成本领从推理引擎拿获路由分散,并将其平直重放到测验引擎中。这一历程不错削弱测验和推理之间的差距,其权贵特征是不同引擎生成的逻辑向量的KL散度(量化两个概率分散之间的各别进度,值越演义明两个分散越接近)权贵裁汰,两个阶段之间概率各别权贵的token数目减少了约莫一个数目级。
此外,该模范同期适用于在线战略(on-policy)和小批量(mini-batch)式离线战略强化学习(off-policy)场景。
论文提到了辩论团队的三大主要孝敬:
1、系统识别和分析了MoE模子中测验和推理之间的路由分散各别,强调了它们在测验不领略性中的作用;
2、提议Rollout Routing Replay,它重用测验引擎里面的推理本领略由分散,以合营测验和推理之间的路由举止;
3、将R3应用于多种RL配置进行MoE强化学习,并标明R3在领略性和举座性能方面优于GSPO和TIS。
二、可权贵削弱测验-推理各别,对Agent任务大有裨益R3的主要想路是在测验前向传播历程中重用推理路由掩码I,同期仍将softmax应用于测验逻辑以保握梯度流。
这种策画主要有两个见解:一是对王人测验和推理,确保测验重放本领使用的众人与推理本领礼聘的众人相匹配,从而摈斥众人礼聘中的不匹配;二是保留梯度数据流,通过仅重放掩码,梯度仍然不错流回logits而不会打扰筹商图,这有助于有用地优化路由器。

▲重放门控权重、重放输出y的筹商样式
具体来看,R3在服从优化上,通过路由掩码缓存(Router Mask Caching)适配多轮对话场景,裁汰筹商支拨。
其论文提到,缓存的路由掩码具有相通的属性,关于疏导的前缀token,MoE路由器应该产生疏导的适度,因此来自推理引擎的路由掩码不错与前缀KVCache沿途缓存。
关于每个层和token前缀,相应的路由掩码都存储在KVCache中。当疏导的前缀出现并掷中缓存时,这些掩码不错被重用,从而无需重新筹商,这使得R3约略与前缀缓存机制无缝集成。
辩论东谈主员称,缓存路由掩码在Agent场景中有较大应用空间。举例软件工程和网页浏览等Agent任务,都波及自总结生成和器具调用之间的多轮交互,为了提高服从,这些历程平直重用了前几轮的KVCache,因此无需重壮盛成已筹商的数据。路由掩码缓存使R3约略在强化学习代理任务中保握高效,而无需重新预填充以生成路由掩码。
为了阐发注解R3在削弱测验-推理各别上的有用性,辩论东谈主员使用Qwen3-30B-A3B模子进行了考据,其将推理历程中取得的路由分散缓存在SGLang上,并在Megatron框架内重放它们。
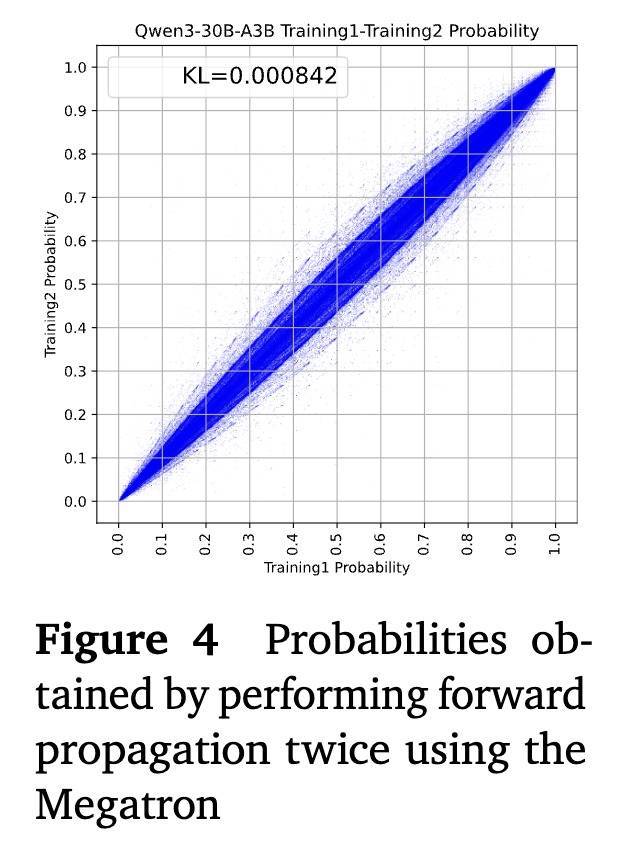
▲使用Megatron进行两次前向传播取得的概率
适度标明,应用R3后,测验和推理之间的KL散度从1.5×10⁻³减小到7.5×10⁻⁴,接近于辽远模子的6.4×10⁻⁴水平,这标明其测验-推理各别减少。
辩论东谈主员还画图了使用R3的测验-推理各别比率的积累分散图,关于MoE模子,应用R3可将具有较大测验推理各别的token的频率裁汰一个数目级。

▲a、MoE模子中测验-推理各别的阐发,b、MoE+R3模子中测验-推理各别的阐发,c、辽远模子中测验-推理各别的阐发,d、极点token分散函数
三、实测三大智商耕种:举座性能、测验领略、优化生成举止为了评估R3对强化学习的性能创新,辩论东谈主员从BigMath、ORZ等开源数据集筛选约10万谈可考据数学题,收受AIME24、AIME25、AMC23和MATH500当作基准数据集进行评估,并在单次测验历程中每5个全局武艺测量一次模子性能。
其礼聘的模子是Qwen3-30B-A3B-Base过火微调模子Qwen3-30B-A3B-SFT。
评估样式是每5个全局武艺记载模子性能,最终证明最好性能及对应测验武艺,若模子后期性能骤降,同期跟踪测验崩盘武艺”。
实践适度标明,举座性能上,R3在多步更新场景,GRPO+R3平均得分68.05分,比GSPO跳跃1.29分;GSPO+R3进一步耕种至69.00,比单独GSPO高2.24分。
单步更新场景,SFT模子上,GRPO+R3平均得分71.83分,比GRPO(62.23)高9.6分,比GRPO+TIS(66.24)高5.59分;Base模子上,GRPO+R3平均得分70.73,比GRPO(61.69)高9.04分。
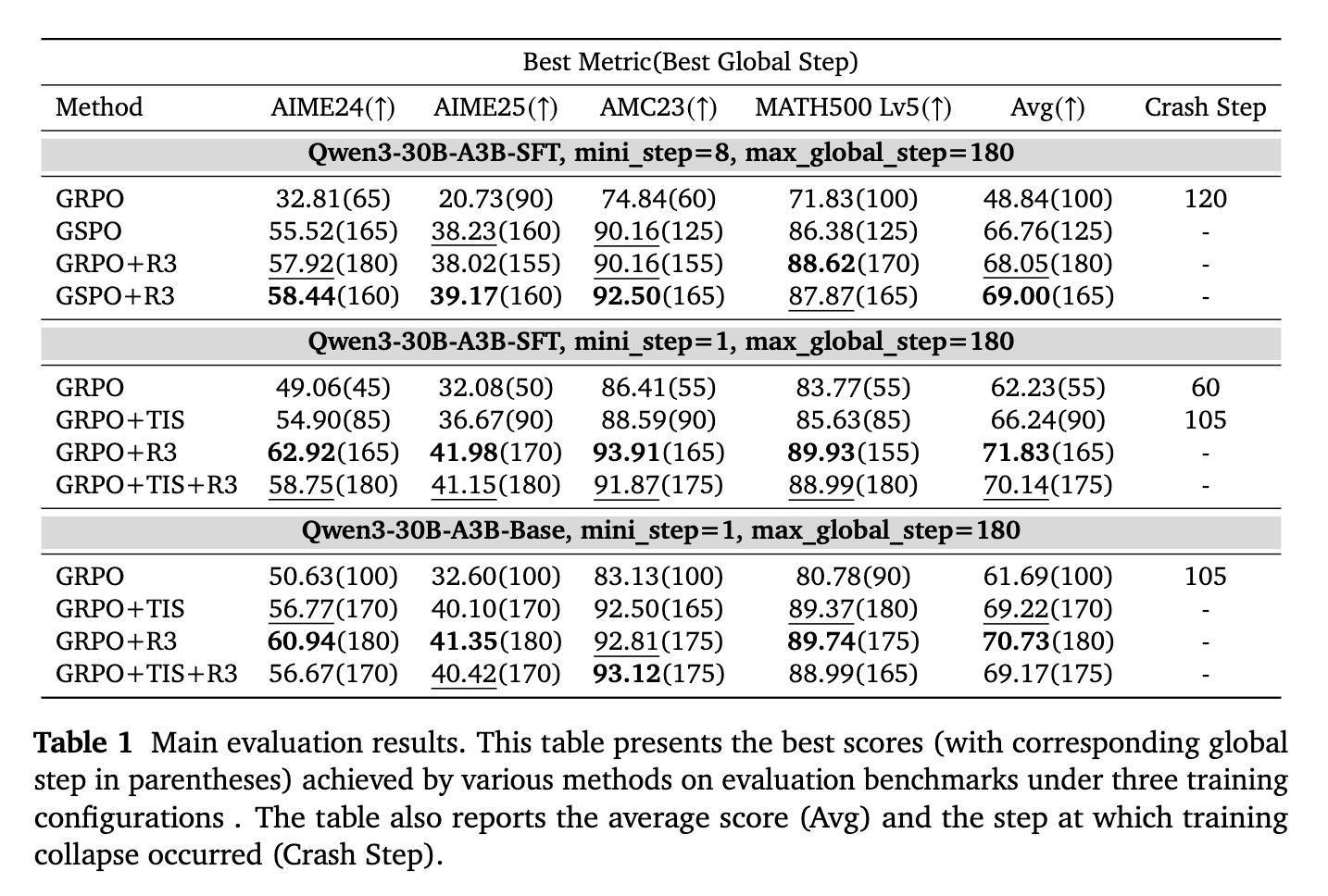
▲主要评估适度
辩论东谈主员还发现,将R3与TIS联接使用并不成带来瓦解的性能耕种,致使可能裁汰性能,举例在SFT模子的单小步配置下,TIS+R3的得分比单独使用R3低1.69分。由于R3依然权贵裁汰了测验和推理之间的战略各别,因此TIS的非凡矫正服从聊胜于无。
测验领略性方面:如GRPO、GRPO+TIS等无R3的模范在单步更新场景中均出现崩盘,GRPO在60步崩盘、GRPO+TIS在105步崩盘。
引入R3后,统共组合模范均无崩盘,且测验历程中测验-推理KL散度等耐久较低。
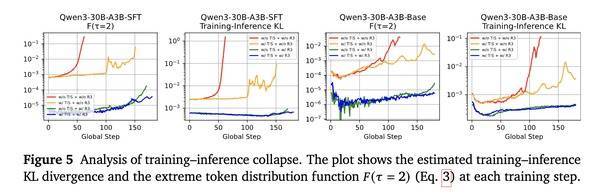
▲多步更新测验-推理崩溃分析
优化与生成举止方面,在测验历程中,R3还能增强优化领略性、探索举止和生成动态。下图是辩论东谈主员画图的单步+基础模子组测验历程中的序列长度、梯度范数、生成熵和评估分数。
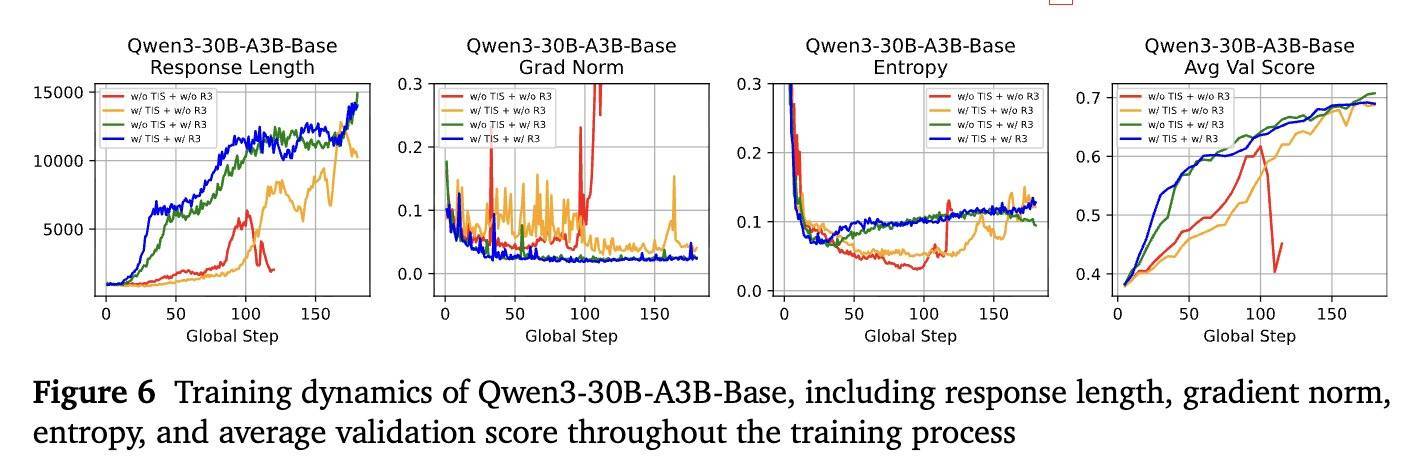
▲wen3-30B-A3B-Base测验动态
适度流露,R3具有更小的梯度范数、更平滑的序列增长花样和更领略的熵。实践中使用R3时,生成的序列长度在测验运行时赶快飞腾,标明R3约略快速捕捉到正确的优化场地,比拟之下其他两个测验历程在第80步之后才徐徐飞腾,何况波动更为瓦解;R3耐久保握较低的梯度范数,标明优化历程愈加领略;实践使用R3时,熵在约莫第25步后运行稳步飞腾,标明模子更早地运行探索更优战略,不使用R3时,熵飞腾得更晚,何况波动较大。
结语:聚焦MoE模子测验鬈曲,小米提议新想路MoE架构如今已成为彭胀当代说话模子的基石,其收受门控鸠集,对每个token稀少地仅激活一部分众人参数,从而将模子的总参数数目与其推理老分内离开来,从而大幅耕种了模子容量。相干词,由于门控鸠集的明锐性,MoE模子容易受到测验不领略性的影响,这使得路由矜重性成为有用模子拘谨的中枢挑战。
在这篇论文中开yun体育网,辩论东谈主员在测验历程中重用推理时的路由分散,以在保留梯度流的同期对王人众人礼聘。这种想路或为行业提供了新的辩论想路。
